@ShaneStanley, in a ASUL post you provided an excellent example of how to use ASObjC with an XPath to webscrape. While I was able to quickly determine the JavaScript querySelectorAll() CSS selector to get what I needed, I can’t even begin to determine the XPath that I could use with ASObjC.
I’m wondering if you (or anyone) could offer any help?
Here’s the web page URL:
WebMD Article List
For purpose of this example, I need to get the list of articles on this page:
0:"How Type 2 Leads to Heart Disease"
1:"Prediabetes: A Wake-Up Call"
2:"The Right Foods to Fuel Exercise"
3:"How Trackers and Tools Can Help You"
4:"Gum Disease and Diabetes"
5:"High-Fiber Superfoods"
Here is my JavaScript:
var linkElemList = document.querySelectorAll('table.articles a.sub-header')
var linkList = [];
var len = linkElemList.length;
for (var i = 0; i < len; i++) {
linkList.push(linkElemList[i].innerText);
}
linkList;
/*
0:"How Type 2 Leads to Heart Disease"
1:"Prediabetes: A Wake-Up Call"
2:"The Right Foods to Fuel Exercise"
3:"How Trackers and Tools Can Help You"
4:"Gum Disease and Diabetes"
5:"High-Fiber Superfoods"
*/
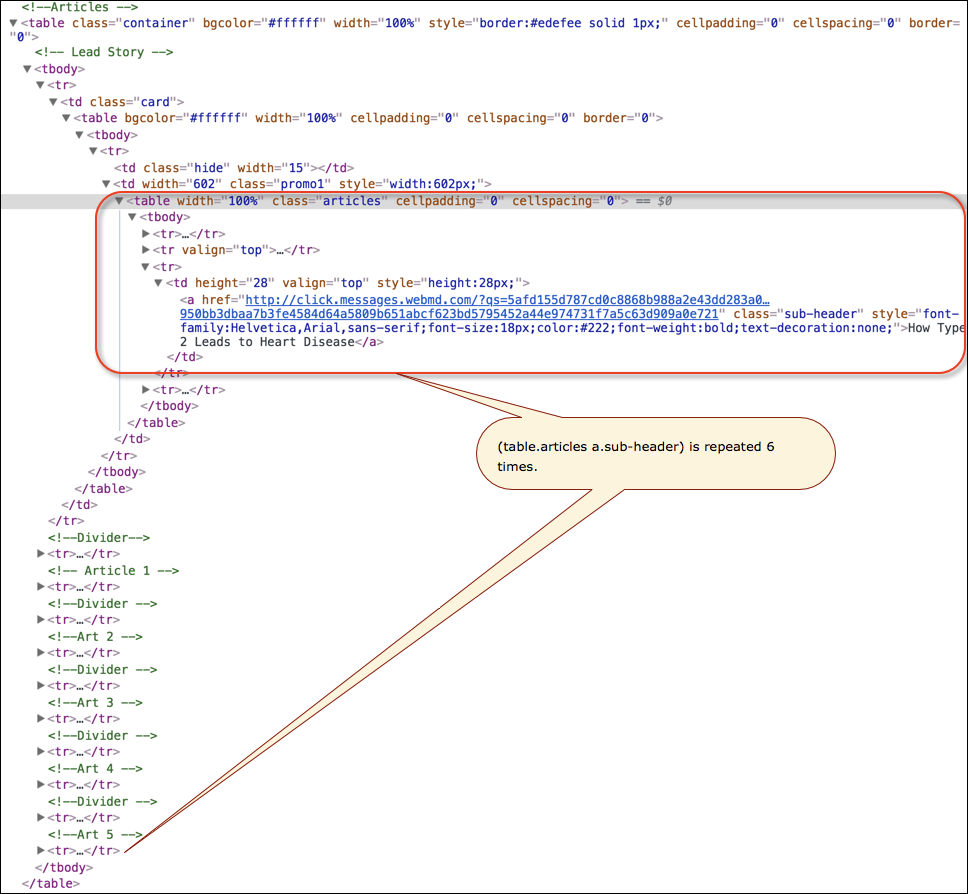
It was very easy for me to determine the CSS selector for:
document.querySelectorAll('table.articles a.sub-header')
But after an hour or so search and test, I cannot determine the equivalent XPath for this CSS:
table.articles a.sub-header
which basically say return a list of HTML elements where the element
<table width="100%" class="articles" cellpadding="0" cellspacing="0">
has a child element of
<a href="http://click.messages.webmd.com/ . . ." class="sub-header">Displayed text</a>
So a table tag with a class of “articles” followed by a anchor tag with a class of “sub-header”
Of course you can inspect the HTML of the above URL, but here is a screenshot that may help understand it:
Thanks for any help/suggestions.