I’m trying to automate a webscrape download of PDFs, and can’t see to figure out an easy way to scrape all of the links from a page loaded into the browser using AppleScript. I would then iterate through the list of PDF links to automate downloading each document. What’s I’m stuck on is an easy way to scrape the list of links using AppleScript. So, for example, if I run the following to load a webpage, is there an easy way to put every link from that page into an AppleScript variable. I’m indifferent on using Safari or Chrome.
use theRoutines : script "Routines"
use AppleScript version "2.4" -- Yosemite (10.10) or later
use scripting additions
global browserChoice
property browserChoice : "Chrome"
set thePage to "http://www.apple.com"
set docText to webPageLoad(thePage)
on webPageLoad(urlLink)
set pageText to ""
if browserChoice is "Chrome" then
tell application "Google Chrome" to tell window 1 to tell active tab
set the URL to urlLink
set isLoading to true
repeat until isLoading is false
set isLoading to loading
delay 0.25
end repeat
set pageText to execute javascript "document.body.innerText"
end tell
else
tell application "Safari"
set the URL of the front document to urlLink
end tell
delay 0.5
set pageLoaded to false
tell script "Routines" to set pageLoaded to page_loaded(20)
if pageLoaded is false then return
delay 0.5
tell application "Safari" to set pageText to text of document 1
end if
return pageText
end webPageLoad
It’s easier to avoid a browser altogether. For example:
use AppleScript version "2.4" -- Yosemite (10.10) or later
use framework "Foundation"
use scripting additions
-- load page
set pageURL to current application's |NSURL|'s URLWithString:"https://www.apple.com"
set {pageHTML, theError} to current application's NSData's dataWithContentsOfURL:pageURL options:0 |error|:(reference)
if pageHTML = missing value then error (theError's localizedDescription() as text)
-- make XML
set {theXMLDoc, theError} to current application's NSXMLDocument's alloc()'s initWithData:pageHTML options:(current application's NSXMLDocumentTidyHTML) |error|:(reference)
if theXMLDoc = missing value then error (theError's localizedDescription() as text)
-- parse for href attributes
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:"//*[@href]/attribute::href" |error|:(reference))
if linkAtts = missing value then error (theError's localizedDescription() as text)
-- filter links to suit, for example
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"http", "/"}
-- extract as list of strings
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue") as list
You need to change the predicate to suit — for PDFs you change the "/" to ".pdf".
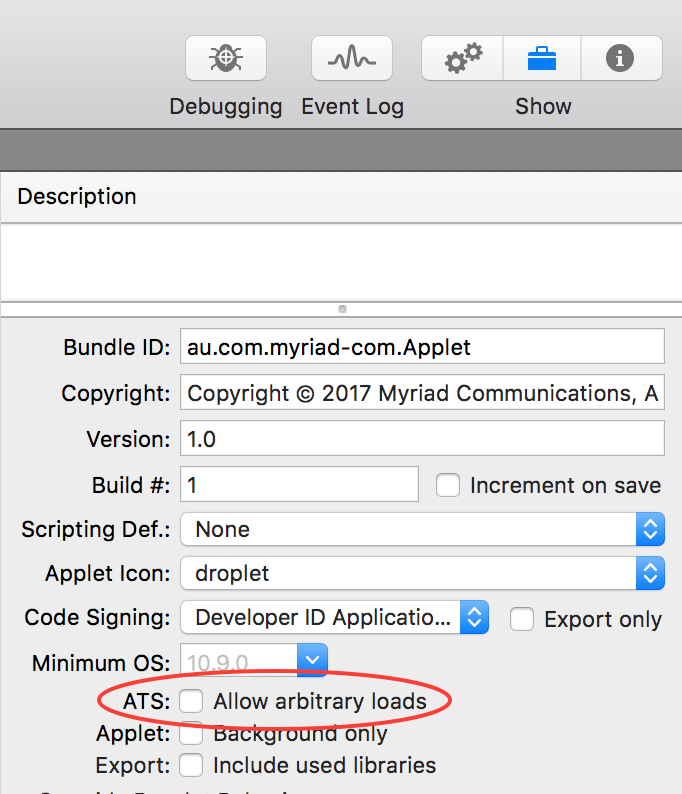
If the site isn’t using https, you will need to go to the Resources tab and turn on Allow arbitrary loads for the ATS setting.
FYI there are a few issues with your script.
Smart quotes don’t work.
No need to declare a variable as a property and a global. Properties are global
The Routines script does something? But I (we?) don’t have it.
The Safari part would never work without the routines.
Both versions are getting plain text, you need source to get the URLs.
I asked for the exact same thing a while back and got the script below (I’m afraid I don’t remember the source, but may have been Shane? )
I’m not sure how to get the source text from Chrome, so I’m only doing Safari
use AppleScript version "2.4"
use framework "Foundation"
use scripting additions
set urlLink to "http://www.apple.com"
tell application "Safari"
set the URL of the front document to urlLink
delay 2
set pageText to source of document 1
end tell
my findURLsIn:pageText
on findURLsIn:theString
set anNSString to current application's NSString's stringWithString:theString
set theNSDataDetector to current application's NSDataDetector's dataDetectorWithTypes:(current application's NSTextCheckingTypeLink) |error|:(missing value)
set theURLsNSArray to theNSDataDetector's matchesInString:theString options:0 range:{location:0, |length|:anNSString's |length|()}
return (theURLsNSArray's valueForKeyPath:"URL.absoluteString") as list
end findURLsIn:
I ran this script, which returns an AppleScript list of URLs of the PDFs on that page.
The script assumes the web page is already loaded, and does NOT download the PDF list. You said you already knew how to do that, so to keep it simple, it just returns the PDF list (6 items).
Questions?
use AppleScript version "2.5" -- El Capitan (10.11) or later
use scripting additions
set jsStr to "
(function myMain() {
//debugger;
var pdfElem = document.querySelectorAll('a[href*=\"pdf\" i]');
var pdfList = Array.from(pdfElem).map(function(x) {return x.href;});
return pdfList.join(\"\\n\");
})();
"
set pdfList to paragraphs of my doJavaScript("Chrome", jsStr)
--~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
on doJavaScript(pBrowserName, pScriptStr) -- @JavaScript @Web @Browser @KMLib
--–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
(* VER: 1.1 2017-11-25
PURPOSE: Run JavaScript in the Designated Browser (Safari OR Chrome)
PARAMETERS:
• pBrowserName | text | Name of brower in which to run JavaScript
• IF this parameter is empty "", then the FrontMost App will
be determined and used, IF it is a browser (else an error)
• pScriptStr | text | JavaScript text to be run
RETURNS: Results of the JavaScript
AUTHOR: JMichaelTX
## REQUIRES: Either Google Chrome or Safari
----------------------------------------------------------------
*)
local jsScriptResults, frontAppName
if (pBrowserName = "") then -- get FrontMost App Name
tell application "System Events"
set pBrowserName to item 1 of (get name of processes whose frontmost is true)
end tell
end if
try
set jsScriptResults to "TBD"
if pBrowserName = "Safari" then
tell application "Safari"
set jsScriptResults to do JavaScript pScriptStr in front document
end tell
else if pBrowserName contains "Chrome" then
tell application "Google Chrome"
set jsScriptResults to execute (active tab of window 1) javascript pScriptStr
end tell
else
error ("ERROR: Invalid Broswer Name: " & pBrowserName ¬
& return & "Script MUST BE run with the FrontMost app as either \"Safari\" OR \"Chrome\"")
end if
on error e
error "Error in handler doJavaScript()" & return & return & e
end try
return jsScriptResults
end doJavaScript
--~~~~~~~~~~~~~~~~ END of Handler doJavaScript ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Shane - I was using SD6. Downloaded SD7 and tried your code with the Allow arbitrary loads checked. Modified both string predicates as needed – the XML doc links were relative – so instead of starting with “http” I needed it to say start with “/docs/” and change the endswith to “.pdf” as suggested.
I also added the necessary code to iterate though the source URL webpages and then to compile the links into one array without any duplicates. Script ran through about 4000 source page URLs in about 8 minutes and gave me 7300 PDF links. Amazing.
What I don’t like is that I don’t understand one bit how to write the code or what it is doing. Is that AppleScriptObjC or is there a resource I can read up on to better understand that code?
Also - I thought I had an easy way to save each of the PDF links to a local folder, but now I’m not seeing an easy way to do so. What would you suggest to automate saving a PDF http link to a local folder ?
Ed - thanks for the input - I was able to get this code to work as well. The browserless option though seems to be much quicker.
I’m pretty much a novice at coding, but I can give you what works for me to get source text from either a safari or chrome page. This code also eliminates the need for the delay 2 step, as it checks the docreadystate of the browser to ensure the page has completed loaded.
For safari - as you’ve noted source of document 1 works inside a tell Safari block.
For chrome - I use execute javascript “document.getElementsByTagName(‘html’)[0].innerHTML”
I call it as a function:
getBrowserSource("Safari")
getBrowserSource("Chrome")
on getBrowserSource(theBrowser)
if theBrowser contains "Safari" then
set the_state to missing value
tell application "Safari"
repeat until the_state is "complete"
set the_state to (do JavaScript "document.readyState" in document 1)
log "busy"
delay 0.2
end repeat
log "complete"
set pageSource to the source of document 1
end tell
else if theBrowser contains "Chrome" then
set the_state to missing value
tell application "Google Chrome"
tell active tab of window 1
repeat until the_state is "complete"
set the_state to (execute javascript "document.readyState")
log "busy"
delay 0.2
end repeat
log "complete"
set pageSource to execute javascript "document.getElementsByTagName('html')[0].innerHTML"
end tell
end tell
end if
return pageSource
end getBrowserSource
Yes, used the direct URL for one task that would take hours using a browser, and took minutes (that was just getting source text, not scraping URLS).
There are two reasons I would use the browser. First, if a user were navigating and wanted to pull all the URLs from the current page they could run a script from the script menu.
Second, some web pages build on demand based in part on what browser and other factors (OS) are detected, and some pages won’t even open without a browser. (We have an internal database search site that simply returns the search page is you send a url directly).
Yes it is, with a touch of XPath doing much of the hard work.
Do you mean the PDFs themselves? If so, probably something like this:
use AppleScript version "2.4" -- Yosemite (10.10) or later
use framework "Foundation"
use scripting additions
-- load page
set pageURL to current application's |NSURL|'s URLWithString:"https://www.apple.com"
set {pageHTML, theError} to current application's NSData's dataWithContentsOfURL:pageURL options:0 |error|:(reference)
if pageHTML = missing value then error (theError's localizedDescription() as text)
-- make XML
set {theXMLDoc, theError} to current application's NSXMLDocument's alloc()'s initWithData:pageHTML options:(current application's NSXMLDocumentTidyHTML) |error|:(reference)
if theXMLDoc = missing value then error (theError's localizedDescription() as text)
-- parse for href attributes
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:"//*[@href]/attribute::href" |error|:(reference))
if linkAtts = missing value then error (theError's localizedDescription() as text)
-- filter links to suit, for example
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"/docs/", ".pdf"}
-- extract as list of strings
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue")
-- define where to save and loop through
set basePath to POSIX path of (path to desktop)
repeat with aLink in theLinks
-- make full URL
set aURL to (current application's |NSURL|'s URLWithString:aLink relativeToURL:pageURL)
-- get name for file
set pdfName to aLink's lastPathComponent() as text
-- download the PDF as data
set {pdfData, theError} to (current application's NSData's dataWithContentsOfURL:aURL options:0 |error|:(reference))
if pdfData = missing value then error (theError's localizedDescription() as text)
-- save it to a file
(pdfData's writeToFile:(basePath & pdfName) atomically:true)
end repeat
It probably needs code to check for duplicate file names, too.
Shane, that’s a very nice, complete solution. Thanks for sharing.
I think I understand most of the script, except for this statement:
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"/docs/", ".pdf"}
Would you might explaining all of the functions and parameters, so I can make intelligent changes in the future?
A predicate is a bit like a whose clause in AppleScript. For convenience, you can use %@ as a placeholder for values, which are then included in the argumentArray parameter. The [c] means ignoring case.
Predicates are powerful, but also a bit complex. But this gives a detailed run-down, with the usual caveat of its being written for Objective-C users:
Hi Shane,
I’m completely a newbie to the programming world, but recently trying to use AppleScript and Automator to do some automation work.
I find this code very helpful, however with use of ‘URLWithString’ it seems can only deal with one Url. I tried many ways to load multiple Urls to run the script, but it will only return the result for the last input Url.
Is there a simple way to make it work for multiple Urls? I’m using it to extract certain Urls from multiple webpages.
Thanks a lot if you can help on this!
Sure — put the code in a handler, and call it from a repeat loop:
use AppleScript version "2.4" -- Yosemite (10.10) or later
use framework "Foundation"
use scripting additions
set theURLs to {"https://www.apple.com"} -- a list of URLs
set posixFolderPath to POSIX path of (path to desktop)
repeat with aURL in theURLs
(my searchPageAt:aURL savingToFolder:posixFolderPath)
end repeat
on searchPageAt:theURL savingToFolder:posixFolderPath
-- load page
set pageURL to current application's |NSURL|'s URLWithString:theURL
set {pageHTML, theError} to current application's NSData's dataWithContentsOfURL:pageURL options:0 |error|:(reference)
if pageHTML = missing value then error (theError's localizedDescription() as text)
-- make XML
set {theXMLDoc, theError} to current application's NSXMLDocument's alloc()'s initWithData:pageHTML options:(current application's NSXMLDocumentTidyHTML) |error|:(reference)
if theXMLDoc = missing value then error (theError's localizedDescription() as text)
-- parse for href attributes
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:"//*[@href]/attribute::href" |error|:(reference))
if linkAtts = missing value then error (theError's localizedDescription() as text)
-- filter links to suit, for example
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"/docs/", ".pdf"}
-- extract as list of strings
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue")
-- loop through
repeat with aLink in theLinks
-- make full URL
set aURL to (current application's |NSURL|'s URLWithString:aLink relativeToURL:pageURL)
-- get name for file
set pdfName to aLink's lastPathComponent() as text
-- download the PDF as data
set {pdfData, theError} to (current application's NSData's dataWithContentsOfURL:aURL options:0 |error|:(reference))
if pdfData = missing value then error (theError's localizedDescription() as text)
-- save it to a file
(pdfData's writeToFile:(posixFolderPath & pdfName) atomically:true)
end repeat
end searchPageAt:savingToFolder:
Hi Shane, since I don’t need download and save data, but just extract the Urls, I finally made it work using below. It’s really efficient without opening a browser. Thank you!
The flow is straightforward, but I tried Automator ‘Get Link URLs from webpages’, sadly it’s not working on a ‘https’ website, not sure if it’s like that or my MacOS(Sierra) version doesn’t support.
use framework "Foundation"
use scripting additions
set urlFile to (path to desktop as text) & "Test.txt" as alias
set urList to (read urlFile as «class utf8» using delimiter linefeed) as list
set FinalResult to {}
repeat with aURL in urList
-- load page
set pageURL to (current application's |NSURL|'s URLWithString:aURL)
set {PageHTML, theError} to (current application's NSData's dataWithContentsOfURL:pageURL options:0 |error|:(reference))
if PageHTML = missing value then error (theError's localizedDescription() as text)
-- make XML
set {theXMLDoc, theError} to (current application's NSXMLDocument's alloc()'s initWithData:PageHTML options:(current application's NSXMLDocumentTidyHTML) |error|:(reference))
if theXMLDoc = missing value then error (theError's localizedDescription() as text)
-- parse for href attributes
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:"//*[@href]/attribute::href" |error|:(reference))
if linkAtts = missing value then error (theError's localizedDescription() as text)
-- filter links to suit, for example
set thePred to (current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH[c] %@ " argumentArray:{"/magazine/20"})
-- extract as list of strings
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue") as list
set the end of FinalResult to the contents of theLinks
end repeat
return the FinalResult
When loading the url “https://www.apple.com”, the line of code to obtain nodesForXPath, assigned the variable linkAtts,
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:"//*[@href]/attribute::href" |error|:(reference))
yields an array of 273 nodes.
The lines of code to filter the array using the assigned predicate
set thePred to (current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"/docs/", ".pdf"})
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue")
however yield an empty array.
How do I correct these commands to find a populated, non-empty array?
You’re getting an empty array because none of the values begins with “/docs/” and ends with “.pdf” — that’s what you’re asking for. What test do you want to apply?
I wrote the following script to obtain a specific node with a local costco pharmacy.
use AppleScript version "2.4" -- Yosemite (10.10) or later
use framework "Foundation"
use scripting additions
-- Obtain page HTML data from URL
set aURL to "https://npino.com/pharmacies/ca/santa-rosa?page=1"
set pageURL to current application's |NSURL|'s URLWithString:aURL
set {pageHTML, theError} to current application's NSData's dataWithContentsOfURL:pageURL options:0 |error|:(reference)
if pageHTML = missing value then error (theError's localizedDescription() as text)
-- Create XML
set {theXMLDoc, theError} to current application's NSXMLDocument's alloc()'s initWithData:pageHTML options:(current application's NSXMLDocumentTidyHTML) |error|:(reference)
if theXMLDoc = missing value then error (theError's localizedDescription() as text)
-- Parse xPath relative values
set PathRelative to "//div[2]/strong/a"
-- Get nodes from XPath for the relative path
set {linkAtts, theError} to (theXMLDoc's nodesForXPath:PathRelative |error|:(reference))
--> results in 24 items
-- Set predicate to filter array of nodes
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH[c] %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"npino", "costco pharmacy"}
-- Filter array using a stringValue predicate
set theLinks to ((linkAtts's filteredArrayUsingPredicate:thePred)'s valueForKey:"stringValue")
--> results in {}
My attempt to filter an array, using the string value predicate format, yielded an empty array from an array of 20 Xnodes.
What might be the correct format for filtering such an array to yield a node listing the Costco Pharmacy, the 5th NSXMLElement, in the array of nodes listed on the web page? My attempt with the following line failed.
set thePred to current application's NSPredicate's predicateWithFormat:"stringValue BEGINSWITH[c] %@ AND stringValue ENDSWITH[c] %@" argumentArray:{"npino", "costco pharmacy"}
Thank you, Shane.
You were correct. My script problem lay not in the Applescript but in the XPath notation. My relative XPath expression descended a bit too far into its children nodes. By substituting
//div[2]
for
//div[2]/strong/a
I resolved the issue, and the script yielded more of the xpath data I was seeking.
Thank you for your help.