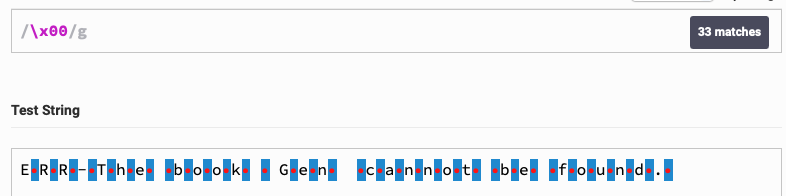
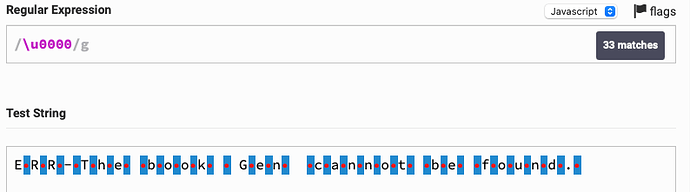
In other words, there are many \x00 signs in the string.
When I paste it to wwwDOTregextesterDOTcom I can search for it. Search for `\u0000’ will also find it.
However, when I use
if myStr contains "\\u0000" then
--Edit: Someone pointed out to me that this is looking for string '\u0000'
-- but not the unicode character,
--but I don't know how to look for the unicode character \u0000
or
if myStr contains "\\x00" then
It does not work. It cannot detect either “\u0000” or “\x00”.
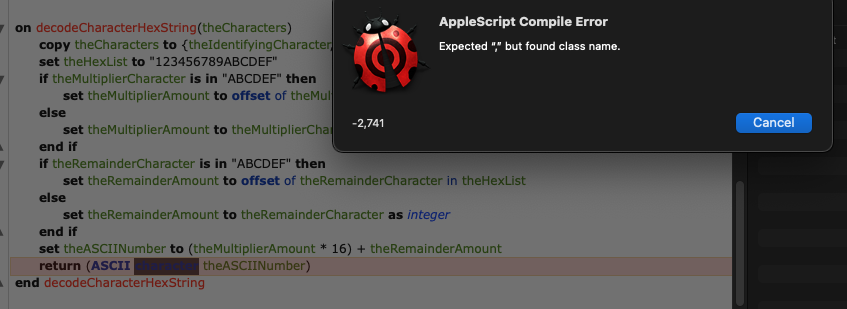
The result in Script Debugger:
(On the left, all results show only “E”. The string is cut off at the first “\x00”).
Some one pointed out to me that it is because utf-16 being parsed as utf-8. But I don’t know how to fix it.
on decodeCharacterHexString(theCharacters)
copy theCharacters to {theIdentifyingCharacter, theMultiplierCharacter, theRemainderCharacter}
set theHexList to "123456789ABCDEF"
if theMultiplierCharacter is in "ABCDEF" then
set theMultiplierAmount to offset of theMultiplierCharacter in theHexList
else
set theMultiplierAmount to theMultiplierCharacter as integer
end if
if theRemainderCharacter is in "ABCDEF" then
set theRemainderAmount to offset of theRemainderCharacter in theHexList
else
set theRemainderAmount to theRemainderCharacter as integer
end if
set theASCIINumber to (theMultiplierAmount * 16) + theRemainderAmount
return (ASCII character theASCIINumber)
end decodeCharacterHexString
I can then call it:
if myStr contains (decodeCharacterHexString("%00")) then