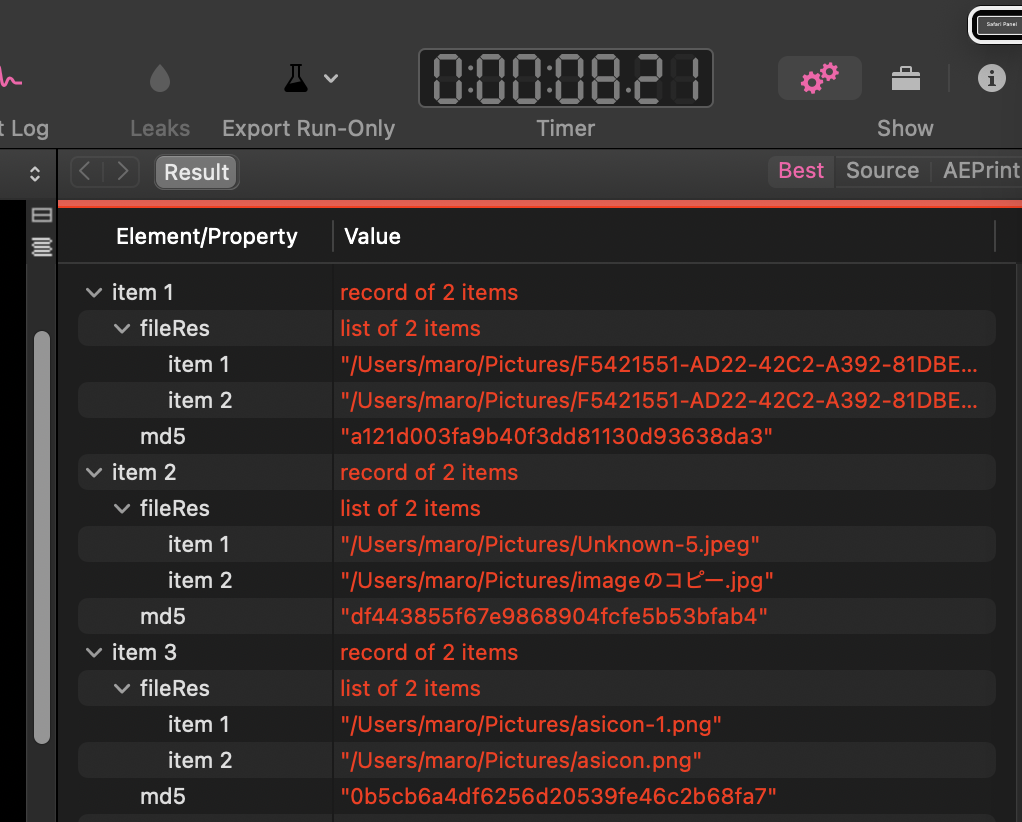
Thank you Per. I would have never thought of using md5 to check for uniqueness. I’ve checked with the 15k files that I had already processed (as you say, Finder is too slow to handle the task smoothly, so I have to work it in small batches) and your script identified 41 duplicates that mine had failed to identify.
I’m running it on the full batch now. 50k files handled in 30 minutes. 45 more minutes to go…
I don’t have a solution that works with 125,000 files but wanted to suggest an approach that works with a smaller number of files.
The following script uses md5 checksums to identify and group duplicates but does that in one running of the md5 utility, which makes it a bit faster. The script doesn’t move any files and instead returns every file that has a duplicate. This allows the user to decide which of the duplicate files to keep.
In limited testing, the script failed when the number of files being processed exceeds about 16,000. Also, when the number of files being processed is large, the script is slow. The script breaks if there is a single-quotation mark in a file path.
--revised 2024.12.19
--returns every file that has a duplicate
use framework "Foundation"
use scripting additions
set duplicateFiles to getDuplicateFiles()
on getDuplicateFiles()
set theFileExtensions to {"jpg", "jpeg"} --set to desired lowercase file extensionns
set theFolder to POSIX path of (choose folder)
set theFiles to getFiles(theFolder, theFileExtensions)
if theFiles = "''" then display dialog "No matching files found" buttons {"OK"} cancel button 1 default button 1
set theData to (do shell script "sha1 -r " & theFiles) --md5 checksums and file paths
set dataString to current application's NSString's stringWithString:theData
set dataArray to ((dataString's componentsSeparatedByString:return)'s sortedArrayUsingSelector:"compare:")'s mutableCopy()
set dataString to (dataArray's componentsJoinedByString:linefeed)
set noDuplicates to (dataString's stringByReplacingOccurrencesOfString:"(?m)^(.+?) .+?(\\n\\1 .+$)+" withString:"" options:1024 range:{0, dataString's |length|()})
set noDuplicates to (noDuplicates's componentsSeparatedByString:linefeed)
dataArray's removeObjectsInArray:noDuplicates
return (dataArray's componentsJoinedByString:linefeed) as text
end getDuplicateFiles
on getFiles(theFolder, fileExtensions)
set theFolder to current application's |NSURL|'s fileURLWithPath:theFolder
set fileManager to current application's NSFileManager's defaultManager()
set folderContents to (fileManager's enumeratorAtURL:theFolder includingPropertiesForKeys:{} options:6 errorHandler:(missing value))'s allObjects() --option 6 skips hidden files and package contents
set thePredicate to current application's NSPredicate's predicateWithFormat_("pathExtension.lowercaseString IN %@", fileExtensions)
set theFiles to (folderContents's filteredArrayUsingPredicate:thePredicate)'s valueForKey:"path"
set filesString to (theFiles's componentsJoinedByString:"' '") as text
return "'" & filesString & "'"
end getFiles
If you’re happy to use ASObjC, NSFileManager has a method -contentsEqualAtPath:andPath:. It checks if they are the same file and then compares sizes, and only compares contents if they’re not the same file or are the same size. Depending on the number of duplicates, that could speed things up considerably.
Thanks Shane for the suggestion. I wasn’t aware of the contentsEqualAtPath method.
Just on a proof-of-concept basis, I wrote the following script, which works as expected but has two flaws. First, the script is slow, and I don’t know a way to fix this. Second, it’s not possible to determine which file is a duplicate of another, although prepending the file size to the file paths might fix this.
use framework "Foundation"
use scripting additions
set theFiles to getFiles("/Users/robert/Downloads/", {"jpg"})
set fileCount to theFiles's |count|()
set duplicateFiles to current application's NSMutableArray's new()
set fileManager to current application's NSFileManager's defaultManager()
repeat with i from 1 to (fileCount - 1)
set aFile to item i of theFiles
repeat with j from (i + 1) to fileCount
set anotherFile to item j of theFiles
set equalityCheck to (fileManager's contentsEqualAtPath:aFile andPath:anotherFile)
if equalityCheck is true then
(duplicateFiles's addObject:aFile)
(duplicateFiles's addObject:anotherFile)
end if
end repeat
end repeat
set theSet to current application's NSOrderedSet's orderedSetWithArray:duplicateFiles
set theDuplicateFiles to theSet's array()'s sortedArrayUsingSelector:"localizedStandardCompare:"
on getFiles(theFolder, fileExtensions)
set theFolder to current application's |NSURL|'s fileURLWithPath:theFolder
set fileManager to current application's NSFileManager's defaultManager()
set folderContents to (fileManager's enumeratorAtURL:theFolder includingPropertiesForKeys:{} options:6 errorHandler:(missing value))'s allObjects() --option 6 skips hidden files and package contents
set thePredicate to current application's NSPredicate's predicateWithFormat_("pathExtension.lowercaseString IN %@", fileExtensions)
return ((folderContents's filteredArrayUsingPredicate:thePredicate)'s valueForKey:"path")
end getFiles
File size and creation date are the only elements that one can use to infer identity.
Now I find myself with the problem of identifying thumbnails of images. I’ve tried to use ImageMagick to see if there could be image elements that could be used for that but to no avail. And I have thousands of thumbnails, and most have a creation date that is not exactly the same as the original…
I think the normal way is to calculate the checksum from the file contents of all the images, and consider the ones with the same checksum to be the same image.
When the contents of the files are the same, it is expected that the amount of operation will increase exponentially according to the number of files.
Also, if you write the checksum in the comment of the image for which the checksum has been calculated once, you will not have to perform the same calculation a second time. You can cache the contents of the calculations.
The name of an image file is arbitrary and does not need to remain. Hence, using the checksum to rename the file considerably reduces the amount of work: if the name is already token the renaming will issue an error and the identical file can be processed independently. There is no need to consider the exponential growth of the possible combinations.
The other problem now is to identify thumbnails. And I don’t know how to do that.
That’s what I mean. I’m not sure from where they come.
I have 15,000 files that are less than 90kb and as such are likely to be smaller versions of bigger files. In some cases, the creation date of the thumbnail is seconds before the creation date of the original. So maybe it is a camera thing.
Anyway, 15,000 out of 65,000 (down from 125,000) is still a significant amount of files. There seems to be a line around 100kb above which the files are not thumbnails but just lowres pictures.
Obviously, manually going through 15,000 pictures is not really an option.
FWIW, I tried the sha1 instead of the md5 utility in the following script, and the former was 55 percent faster when processing JPG files. However, if the files being processed were PDFs, the difference was negligible. This script worked correctly with a folder that contained 43,024 files including 23,808 PDF files, although it took 139 seconds to complete its work. This script returns all files that have a duplicate and groups the files by their checksum values, which allows them to easily be moved or otherwise manipulated.
--revised 2024.12.19
--returns every file that has a duplicate
use framework "Foundation"
use scripting additions
set duplicateFiles to getDuplicateFiles()
on getDuplicateFiles()
set theExtensions to {"jpg", "jpeg"} --set to desired lowercase file extensions
set theFolder to POSIX path of (choose folder)
set theFiles to getFiles(theFolder, theExtensions)
set theData to current application's NSMutableArray's new()
repeat with aFile in theFiles
set aLine to do shell script "sha1 -r " & quoted form of (aFile as text)
(theData's addObject:aLine)
end repeat
(theData's sortUsingSelector:"compare:")
set dataString to (theData's componentsJoinedByString:linefeed)
set dataNoDuplicates to (dataString's stringByReplacingOccurrencesOfString:"(?m)^(.+?) .+?(\\n\\1 .+$)+" withString:"" options:1024 range:{0, dataString's |length|()})
set dataNoDuplicates to (dataNoDuplicates's componentsSeparatedByString:linefeed)
theData's removeObjectsInArray:dataNoDuplicates
return (theData's componentsJoinedByString:linefeed) as text
end getDuplicateFiles
on getFiles(theFolder, fileExtensions)
set theFolder to current application's |NSURL|'s fileURLWithPath:theFolder
set fileManager to current application's NSFileManager's defaultManager()
set folderContents to (fileManager's enumeratorAtURL:theFolder includingPropertiesForKeys:{} options:6 errorHandler:(missing value))'s allObjects() --option 6 skips hidden files and package contents
set thePredicate to current application's NSPredicate's predicateWithFormat_("pathExtension.lowercaseString IN %@", fileExtensions)
return (folderContents's filteredArrayUsingPredicate:thePredicate)'s valueForKey:"path"
end getFiles
I assume you don’t really need these “thumbnails” so I wonder if you can just delete any file that’s 90 K or less? Or are you still not sure if all such files are thumbnails?
I don’t need the thumbnails but there is no rule that says any file that is below 90kb is a thumbnail of a bigger file… It looks like the minimum size for a “normal” jpg is around 100kb, though.
So I’d like to find a systematic way to analyse such small files.
My naming pattern is the following:
YYYYMMDD-HHMMSS-(size)-(real size).EXT
are two files created 3 seconds apart, and the second is a thumbnail of the first.
I checked their info with ImageMagick and did not find anything that I could use to match them though.
I could check for small files and see whether they have a bigger file that was created a few seconds apart, but that seems to depend on the camera. Since some thumbnails seem to be created at import time, and not in the camera at shooting time…
If I understand your requirement correctly, then you’ll need to find an AI tool that will compare two images and conclude whether they’re identical visual-vise even if one of them is a smaller copy of another.
(It’s quite possible there’s an easier solution that will be suggested by others.)