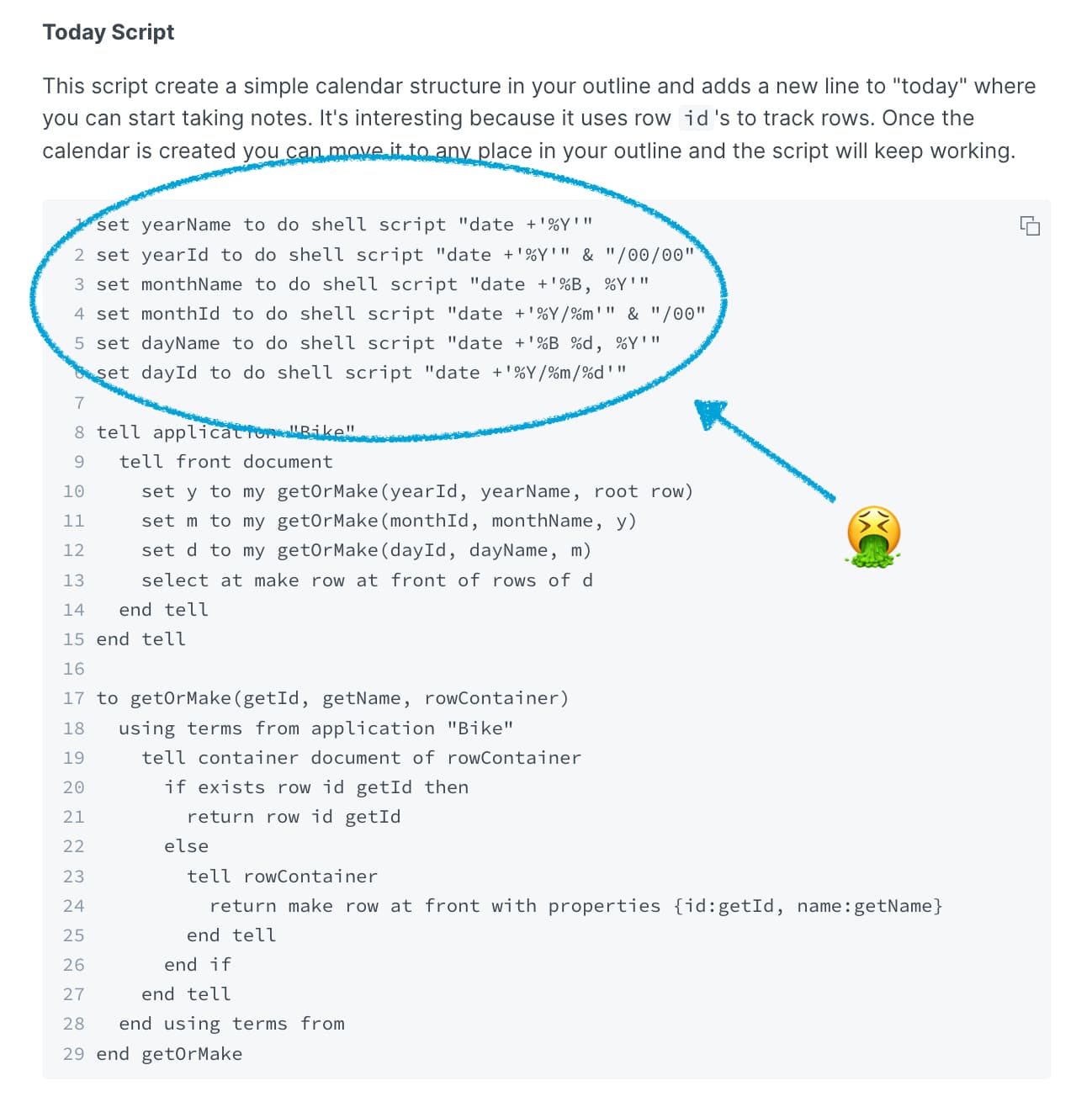
The first released Inter-application scripting system for Mac (pre OSX) was Frontier, from Dave Winer, which what based on and/or inspired by his outliner program.
There are probably others who could do a better job explaining it than I could.
I’d like the dictionary language to make sense, or be well explained.
I’d like it to be easy to script
and, most importantly, I’m imagining how I would use this in practice and what scripting capabilities would I want.
I’m also thinking about additional features I’d like. (You know, more work for you!)
So the script below works off of the default text.
First, I have no idea what a hoisted row is, or the distinction between a child row and a row. (In a sense every row is a child row of something, and some rows have child rows).
With the script below it seems to treat every row and child row the same, until it comes to the row with the URL, then it seems to stop counting child rows.
Also, the property name is not really a name. What you have as name should be something like contents
name should be a user settable property of a row (or child row) that returns "" or mising value until the user sets it.
set the name of row x to "TV Channels"
I’d really like to see the selection options ironed out.
(I would suggest looking at BBEdit, or Script Debugger for dictionary inspiration).
I like the fact that the file format is html, but it doesn’t have a way to edit or show any text formatting.
Might also be nice to set the contents of a row to something other than text, like an object (a graphic, or a button, or a field).
I can see a few uses for this right out of the box, but I also see a huge potential.
tell application "Bike"
tell document 1
set rowText to {}
repeat with x from 1 to count of rows
set the end of rowText to name of row x
if not (x > (count of child rows)) then set the end of rowText to name of row x
end repeat
end tell
end tell
Also, forgot to mention, it would be really nice if the folding system in Bike also worked in a browser. Dropping the doc on Safari, the folding icons turn into bullets or hollow bullets.
First things first: Remember that your Apple Event Object Model is a relationship-based graph, not an Object-Oriented DOM. If you try to think about it in OO terms, you will only hurt yourself. If you use OmniOutliner as a design reference then look at its AppleScript dictionary, not at its JavaScript API. Omni’s JS APIs use OO DOM design patterns so are not applicable here. (I can’t comment on the design or quality of OmniOutliner’s AS dictionary as I don’t use it myself, but ISTR Omni being better than average at implementing AppleScript support in general.)
…
Child rows will appear as row elements of the row class. Remember: element names are fixed, being the singular/plural form of the class name. Therefore you cannot model both the immediate children and all descendents as elements of row.
class:
row -- a single entry in an outline document
elements:
row -- this row's immediate children
properties:
container : reference -- this row's parent row
entire contents : reference -- all rows contained by this row
See Finder’s container class for reference. In terms of relationships, a row object has:
a one-to-many relationship with its child rows
a one-to-one relationship with its parent row†
a one-to-many relationship with all its descendents
BTW, I can’t tell you the [Cocoa app] design pattern for implementing the entire contents property in CocoaScripting because I don’t know it myself. (Frankly CS is a boat anchor.) Mark has spelunked the CS framework in the past, trying to push its naive behavior beyond its implicit assumptions and built-in limitations; perhaps he can advise.
All I can say is that is how the app’s AEOM should look and feel from the user’s POV. Actually implementing that behavior using CS, and getting it 100% correct, is mostly left to the poor developer.
It may be that CS forces you to implement the entire contents property as a list of single-object references (which CS-based apps often do), as opposed to a single multi-object reference. That UX sucks: client-side iteration forces the scripter to write a bunch of boilerplate repeat loops and drops script performance in a hole. While sometimes that’s unavoidable (e.g. setting the name property of each element to a unique string), when the same command is being applied to multiple objects it’s best for the application to handle the details.
For instance, let’s mock a delete command which says to the app “recursively delete all rows that don’t have any content”.
tell application "Bike"
set theRow to …
delete every row of entire contents of theRow whose note = "" and rows = {}
end tell
(Assume note is a property which contains the row’s user-supplied text.)
BTW, AppleScript syntax is weird and allows where clauses to appear out-of-line, so what that command is really saying is this:
delete (rows where its note = "" and its rows = {}) of entire contents of theRow
Very powerful query, much like an SQL DELETE from <some container> WHERE <some test>.
Of course, an RDBMS only has to operate on a flat unordered set of records, whereas you may be implementing your AEOM over ordered NSArray<BKRow> collections, so ensuring your app performs each deletion in the appropriate order is left to you‡.
BTW, this is probably the point that you as developer decide to implement entire contents the lame dumb way (list of single-object references) purely for sake of getting your app on sale this side of Xmas, and let the scripter eat the full cost of using it. Implementing a second-rate AEOM is a lot quicker, cheaper, and easier than implementing a top-quality one, and most users will just be happy to get one at all. But that’s the tradeoffs you make as a businessperson who needs to sell product to justify the hours spent developing it.
–
† One caveat is how the root row object represents its parent. Assuming the root row object is represented as a property (i.e. one-to-one relationship) of a document object, then the root row’s container should be a one-to-one relationship to that document, whereas every child row’s container will be a one-to-one relationshipt to its parent row.
BTW, you might feel tempted to make the root row’s container missing value, which as a programmer would probably be your first instinct as that’s how your underlying OO Model would no doubt expose a BKRow instance’s container were you implementing a container property for ObjC/Swift use:
@property (readonly) BKRow * _Nonnull container;
var container: BKRow? { get }
But again look at your UI/UX from the user’s perspective and observe the principle of least surprise. In the GUI, which is what scripters will naturally use as their reference, all rows are contained by something; the only difference between a root row and every other row is the container’s type: a document instead of a row. The downside is you may have to write a bit more CS code to represent this more sophisticated abstraction to the user (since CS, despite being a ViewController framework, has some painfully tight coupling to the app’s Model); or you can punt it for sake of getting the product out the door and most customers will be psyched just that you bothered at all.
‡ CS-based apps are often good at effecting move/duplicate/delete commands in unsafe/incorrect order, causing bits of the user’s data to end up in the wrong position or even vanish entirely; a smorgasbord of off-by-one related errors. e.g. Try delete (every word where it contains "e") on a TextEdit document for hilarious results. So the poor script ends up having to do all the iteration itself anyway, just to work around the app’s and/or CS’s implementation bugs.
id property looks okay (I’m assuming GUID string); it’s also good as it means users can get a stable reference to a row anywhere in the document [1]
link property should be named URL [2]
level looks fine
the name property I’m not sure about; there are probably arguments both for and against, pertaining to how outliners are used by their users. I suspect leaf nodes typically contain arbitrary text of arbitrary length while parent nodes typically contain ad-hoc hierarchical headings. However, unless a row in the GUI supports separate “heading” vs “body” fields, using name is probably the least worst choice as it supports row named “Some Ad-hoc Heading” reference forms.
document
you can either have row elements OR a root property, not both. Which is appropriate really depends on:
How the app’s structure is presented in the GUI. If an open document has a single top-level row, which the user can expand or collapse, and only create child rows beneath it, then it makes sense to present that row as a root property. Or, if the GUI never reveals this “special” node to the user and presents its children as zero or more rows visible in the document window, then present those rows as elements of the document.
The nature of the root node. Does it have special characteristics that distinguish it from all other nodes (e.g. is it text-less, and exists in the Model only to serve as container)? Or is it an ordinary node exposing the exact same user-visible attributes as every other node?
again, get rid of child rows elements
id fine
root row – If you are exposing the root row object as a document property, I would just call that property root. That it contains a row object is already apparent from its type; and you don’t have a type named root so there’s no need to wrangle the property name to disambiguate the two. Two other property names worth considering: top row, outline. The word “top” better reflects the visual structure and may well map better to a typical user’s mental model of an outline. (“root” is a very programmer word, so only appropriate if this app is aimed specifically at techies. For everyone else in the world, it means “at the bottom of a tree.”) Or, from a branding POV if nothing else, I would consider outline, which is both descriptive and suggests this is the most important property in there.
hoisted row – I have no idea what this means (hint: even if the term “hoisted” is familiar to existing outliner users, the description text you’ve provided is entirely useless)
focused row – I am unclear how this differs from selection
selected text, selection row, selection rows – this is obviously a mess, but I’m assuming you’ve just thrown them all in for purposes of comparison and will eventually whittle down.
application
font size, background color, foreground color – The properties look fine, but the nature of their descriptions suggests they could/should be amalgamated into a single, self-explanatory preferences object class which is exposed as a preferences property of application. Whether you think that worth doing depends on whether you expect to add more application and/or preference properties in future.
Also, if in future you might make each window’s visual appearance individually customizable, factoring these attributes out into a discrete object now makes sense. One might then name the document’s property appearance, the application’s property default appearance, and the record type or class appearance options.
collapse/expand – get rid of these commands and add a single boolean property to the row class, named either collapsed or expanded depending on which is the more intuitive. e.g. To shallow expand row elements:
set expanded of every row of someRow to true
To collapse an entire subtree:
set expanded of [every row of] entire contents of someRow to false
select – I know it’s pretty common to see this command in apps that support scripting selections, but again if users can set a selection via a document’s selection (read-write) property then it’s really redundant. Also, if you do keep select the row(s) to select should be passed as the direct parameter; there should not be an at parameter. (The document is already specified by the row reference.)
One reason you might want to provide a discrete selection command: select myBikeURL. While the same operation may also be expressed as set selection to every row whose URL = myBikeURL, the explicit command form is much shorter and more convenient.
import – Get rid of this. The idiomatic operation is to open both documents in the app, then e.g.:
duplicate rows of document "Foo" to beginning of rows of document "Bar"
The only reason you might want a discrete import command is for opening a foreign-format file and for some reason can’t express the transcoding options as an optional with options parameter to a standard open command. (Again, AS and CS might make extending standard commands with custom parameters excessively painful, necessitating a fallback to some awkward UX kludge just for sake of making it work at all.) For example, when reading an outline from a web URL or other non-filesystem-based resource.
(Alas, macOS and AppleScript really show their age when it comes to reading and writing file-like objects from anything other than a traditional mounted disk. There’s no reason in principle that open and save commands couldn’t accept non-file URLs, but good luck explaining to both that it isn’t the 1980s any more.)
export – Again, I’m inclined to say get rid of it: a standard save command can express the file format. The only caveat is if users will frequently export fragments of a document, in which case export ROW[S] to FILE as FORMAT is obviously more convenient than copying the desired rows to a new, empty document and saving that.
Oh, and there’s no reason to call the file format enumeration saveable file format. Just file format is fine. Also consider if the enumerators really need the Format suffix. (It’s probably best to keep it, just to avoid any keyword conflicts with type names, although the word “format” should probably be lowercased.)
Your open/save/etc commands should also probably be able to infer most if not all documents’ file type just from existing file name extensions (e.g. foo.opml), so if there is no explicit as property then use the file name extension if possible and only fall back to a default type if neither is available. When saving a file with neither explicit as parameter not file type extension, the default should probably be native Bike format to avoid any possible degredation of the user’s data. When opening an unknown file, you could always try sniffing the first few bytes to see if it looks like a native Bike or OPML XML, and treat as plain text if it’s obviously neither.
–
[1]
[2] Were CS and AS better designed and used coercions properly, this property wouldn’t be needed as one would just say get row X of row Y of document Z as URL and the get command would return a URL string instead of an object reference. But they aren’t and they don’t, so an explicit URL property is the best option.
To be clear … rows is same idea as entire contents idea, just implemented as a element instead of as a reference. On the other hand child rows is an element of directly contained rows.
To me they are still both necessary because:
I need rows for nice efficient implementation. In particular they allow:
Me to return global row references that are fast to create, resolve, and are stable as rows move about the outline:
row id "3C" of document "Untitled"
Users to quickly and efficiently find rows anywhere in the outline by id such as:
row id "todos" of document "Untitled"
I need child rows because otherwise I find it confusing when trying to manipulate the outline. For example if I only have the rows element and I have this outline:
hello
one
a
two
three
Now let’s say I want to make a new child of “hello” after “one”. If I have the child rows collection then it’s pretty easy I can do something like:
tell "hello" to make child row at after "one"
On the other hand if I only have the rows collection then I’m not sure what to do. I might try this:
tell "hello" to make row at after "one"
Maybe that would work, but I think it would instead insert the new row after “one”, but before “a” which is not that I want. Also it’s unclear to me what level it would be inserted at. I could resolve these by creating the row and also passing in a value for level, but figuring out the proper level is difficult I think.
If there’s a clear way to specify all outline locations using just the rows collection then I would be happy to drop child rows, but I don’t see that yet.
What if I keep my current design, but mark child row as hidden. I’ve just tried that and things still seem to work.
That would allow me to keep these two element collections, but the child row class no longer shows up and confuses in the dictionary class listing.
Yikes! I’m looking for you to tell me the features I can take away :). That’s my goal right now… make it as minimal as possible, without messing up the foundation too much. Then can incrementally add features over time as needs arise.
I’m going to add a conceptual overview to the Bike User’s guide and will link to that from the scripting dictionary. I think some concepts such as “hoisted”, “focused” are better described there where I can have more space and pictures.
Bike’s data model is very simple. Pretty much:
Row
content: SingleLineOfText
children: [Row]
That’s unlike some outliners that distinguish between a “heading name” and then attached content. In Bike every line of visible text is a row, there’s no separate attached content.
So you are right that the text this is “content”, but from a user’s perspective many rows have a name (Todos, January, House, etc), and I think it’s nice to use AppleScripts build in “name” support to access these rows by name.
For other rows name doesn’t make as much sense, but I still think it’s worth using name for the above reason. The data model isn’t going to change to allow for a separate name field, so that’s why I’m using name to access content as plain text right now.
In future (as rich text and maybe row types are added) then I will add a new content field of type rich text. So name will continue to be a plain text view of the content, content will become a richer view.
I do plan to add rich text support, but that will be added after the 1.0 release.
I’m not sure about interactive elements, but I do plan to support for alternative row types in future such as “heading”, “separator”, etc. Again these are future things after 1.0 release.
I think this should be possible, but I don’t have time to work on it right now. The solution will be to create a stylesheet that makes the HTML list look like Bike, and a JavaScript that will collapse, expand those rows. With those files hosted on a CDN then I would just add those links to Bike documents. Free licenses to anyone (and there friends!) who makes that
I will add some conceptual documentation, but for now consider this outline:
Yard work
Garden
Weeding
Planting
Rake Leaves
In this example outline rows of document is everything you see. On the other hand child rows of document is only “Yard work”. Or if you are accessing the “Yard work” row then rows are the four rows listed under it, and child rows are “Garden” and “Rake Leaves”.
child rows are the direct content of the container (container is document, or another row)
rows are the entire recursive content of the container
Please see my latest discussion with @hhas01 for why I think these distinct collections are both needed. Let me know if there’s a better way.
“Hoisted” is when you don’t want to see your entire outline, it’s a view operation that doesn’t effect the model. For example if you hoist “Garden” then your view view will only show “Weeding” and “Planting”.
In your script you are comparing x (which is a row count based number) with count of child rows. I don’t think this generally makes sense to do.
I’m not quite sure what you are trying to do. Here’s a similar script that collects the names of all rows that have children:
tell application "Bike"
tell document 1
set rowText to {}
repeat with x from 1 to count of rows
if ((count of child rows of row x) > 0) then set the end of rowText to name of row x
end repeat
end tell
end tell
You’re asking us how to implement a good idiomatic AEOM. That’s what I’ve given you. If you want to bend it into some weird mess then you certainly do so, though honestly I don’t see what it gains you over doing it the right way.
If you want any given row object to be able to reference all of the nodes in its subtree, putting an entire contents property onto every row object is the way to go. (And also onto document if the root node is invisible, with its children visible as row elements of the document.) This design is simple, powerful, and uniform; everything users love in a good AEOM. e.g. See the entire contents property of Finder’s container class. The only issue is implementing that property within the CS framework, given CS is dumb as rocks and as flexible too.
OTOH, if you only needed to provide direct access to all nodes from the document object, you could define row as elements of document and have that provide a flat view of the entire outline. You can then expose the outline’s top (root) node as an outline property for those who want to traverse the hierarchy themselves, with each node providing access to its immediate children only. e.g. Adobe Illustrator does this for a document’s page item elements. This is not as intuitive to use as entire contents though, and it’s less powerful, of course. So I would still recommend the first way.
…
hello
one
a
two
three
Your mock code for this is not valid AppleScript. At any rate, assuming the “hello” node is the document’s root node presented as an outline property which cannot be created or deleted, the user would create new nodes using commands such as these:
make new row at (beginning of rows of outline) with properties {name: "one"}
make new row at (end of rows of outline) with properties {name: "three"}
make new row at (after row "one" of outline) with properties {name: "two"}
make new row at (end of rows of row "one" of outline) with properties {name: "a"}
I forget the extent to which CS allows users to omit parts of an insertion location specifier and infers them automatically from the rest of the reference. For instance (and continuing to assume your AEOM has an explicit root property named outline), the user might shorten the end of rows of outline reference to end of outline, rows of outline, or even just outline, expecting your app to take care of the details for them.
For instance, if the end of portion (insertion location) is omitted, the command might default to whatever’s the most logical insertion point, typically beginning or end. e.g. With Finder, you don’t need to specify beginning/end/before/after when making/moving elements, just the container into which they will go. However, since your outliner’s row elements are highly order-sensitive, you may prefer to insist the user always specifies an insertion point (beginning/end of rows, before/after row) and throw an error if not. A bit bureaucratic, but leaves nothing to assumption or guesswork.
At any rate just go with whatever behavior the standard framework provides, matching if you can the same default behaviors the user experiences in the GUI.
Replying to parts I’m not sure about, I’m applying quite a bit of this feedback, thanks.
I considered this, but I think it would have performance problems. For example here’s a “Cleanup” script that I wrote:
tell front document of application "Bike"
set savedSelection to selection row
collapse at every child row with completely
select at savedSelection
end tell
With the collapse command its instant and easy to collapse everything. In the above case I can collapse everything and it’s just a single command that’s sent from AppleScript to my app, very fast.
If collapsed becomes a state attached to row then it becomes a lot more expensive. For example if the outline has thousands of rows then they all need to get shipped to AppleScript layer, mutated, shipped back to Bike, and then apply changes to model.
Well, I was going to keep them all :). I feel like they are all different and important views of the selection. I did originally have them as properties of a more generic “selection” object, but wasn’t sure how that really improved things, and it made it more verbose to access the selection.
I agree if I’m just selecting rows than a property or direct parameter is simpler. Why I like using a separate command that with document as direct parameter is that it doesn’t lock me in to selecting row types. I can add other at types in the future. For example I was going to support selecting by line/column range and I still might in the future. That could be added easily to the current selection command without breaking anything.
I think they can still be useful for performance and working with other applications. The intention isn’t so much to export to and import from files or documents. Instead the idea is to be able to quickly turn a part of my outline into a standard format that I can share with another other app.
Outlines can be big and have a variety of content. Maybe I want a script that quickly turns my “top 10” section into a public web page. I can do that with a quick export and post the string to the web. On the other hand duplicating those items to a new document, saving as a new format, etc is just much harder.
Generally, all of Bike’s import/export formats are open HTML/OPML/Plain Text and so likely to be useful to / or available from other apps. Allowing quick export of a chunk of your outline to another location in a standard format is pretty useful I think.
I agree it’s weird, but that’s a type that I’m importing from the standard cocoa scripting terminology through this line in my .sdef:
The CocoaStandard.sdef linked above is handling all the document load/save format behavior. I’m not sure what it’s doing, but I will probably just use it’s standard behavior without any changes.
Remember: AEOM is a very high-level end-user-oriented ViewController abstraction layer, with a particular focus on multi-object queries. The UI it presents to the user may track the Model implementation very closely (thin abstraction), or it could be wildly different that does a ton of work to present the raw program data in a way that the user finds logical and intuitive (thick abstraction).
For instance, the standard Text Suite has character, word, and paragraph classes, but these bear zero resemblance to how the backing store is actually implemented (e.g. one big linear char buffer, or maybe an NSMutableAttributedString if you’re really pushing the boat out). These so-called “classes” are just thick abstractions for building queries that will search through all those chars to find the portions to manipulate. Yes it’s a chore to implement such a thick abstraction—even harder to make it rock-solid reliable as fast as well. But compare it to “automation” APIs that require the user to wrangle a raw “cursor” and manipulate that buffer via the same low-level [Obj]C[++] Model API that the app’s GUI uses internally, and you’ll appreciate the huge difference in end-user UX that the high-level abstraction provides.
BTW, don’t know if you already know of it, but if you don’t:
Technical Note TN2106: Scripting Interface Guidelines. Basically to AEOM what Apple’s HIG was to GUI (at least back when Apple still cared about consistency, legibility, etc, etc). Worth a skim.
Anyway, getting back to implementation…
There is nothing to say that under the hood your AEOM can’t recognize set collapsed of entire contents of someRow to true as a single collapse operation performed on an entire subtree and optimize that to the appropriate Model method call. You don’t say what you’re using for a backing store or what sort of internal methods your Model presents to your graphical and scripting ViewControllers for their use.
Of course, if you leave CS to do things its own way, it will insist on iterating every single object (real or virtual) and thereby taking forever, because CS really is thick as mince. (This is also why CS’s standard Text Suite is complete garbage for both reliability and performance. To call CS’s implementation “naive” is…well, naive.) The only question for you is whether it is worth overriding the standard GetCommand, SetCommand classes to be considerably less dumb. Or it might be that internally you could implement an BKEntireContents class that dumb old CS thinks is a single object, essentially a facade/shim for whatever fast set operations magic your app uses internally. I can’t tell you how ’cos the CS framework is not something I’ve used (I develop automation workflows and languages, not GUI apps). I just know it’s “adequate, just about”, as long as you don’t ask its crappy Text Suite to do any heavy lifting or don’t do anything that involves operating on lots of “objects” at once where it really starts to drop the ball (both for reliability and performance).
Well, no. The fact you have so much overlapping behavior in 3 adjacent properties is an obvious design/code smell. Figure out what it is you want to present to the user, in terms of what does the user expect to do with it, and implement that. That’s just good UI/UX design, no matter the medium (GUI, web-based protocol, Apple events, etc).
You should be able to achieve everything with a single property on application and or document classes:
selection : reference
What that selection actually is can be resolved during Get/Set operations. e.g.
get selection of document 1
can return a single multi-object reference, a list of single-object references, or a string. For my money, it is best to return a single multi-object reference if the selection is contiguous, as that’s vastly more efficient if the user is just going to pass it back to the app in another command, e.g.:
tell document 1
set selectedRows to selection
move selectedRows to end
set collapsed of selectedRows to true
end tell
or, if it’s just the one command actually:
tell document 1
move selection to end
end tell
The user can also change the selection by setting the property to a new reference:
tell document 1
set selection to rows 3 thru -8
end tell
And if the user does want a list of single-object references:
tell document 1
get every row of selection -- returns a list of `row` references
end tell
or a list of name properties:
get name of every row of selection -- returns a list of strings
Query-oriented UI FTW.
OTOH, if your app allows non-contiguous selections then you really have no choice but for get selection to return a list of single-object references. That said, you should still type it as reference so that users can write stuff like:
tell document 1
tell selection
move to end
set collapsed to true
end tell
end tell
It only resolves to a list when a get is performed. Even then, you still want to support query-oriented behavior up to the point where it’s finally crunched down to a list so that, e.g.:
get name of every row of selection
will still return a list of strings. (If the selection property is typed as a list, the user can’t do that; they have to get that list and then iterate it themselves. Tedious and slow both to code and to run.)
Now, when it comes to getting the selected rows’ text as a single contiguous string, best way to do that is by requesting the type in the get command:
get selection as string
In addition to being a built-in AS operator, as is also an optional parameter to get. It’s not normally shown in dictionaries, but will arrive in the core/getd AppleEvent record as the property keyAERequestedType. (I don’t recall if CS’s standard NSGetCommand implementation does anything with this parameter, never mind it doing something logical and helpful. You’ll have to dig into the docs to find out.)
…
Like I said at the beginning, implementing a JavaScriptCore API will likely be quicker and easier than implementing an AEOM UI; though perhaps I should have qualified that as “a good AEOM UI”, which allows the possibility of implementing a not-so-good one quite a bit quicker.
–
p.s. I will also leave this here:
It’s a paper by one of AppleScript’s original designers that sheds more light on how Apple event IPC and the AEOM works and why it was designed to work that way. Had Apple mgt not pissed off Cook and Harris right as AS 1.1 was going out the door, they might not have walked out immediately after it, taking all their institutional knowledge with them. And perhaps today we’d have top-notch comprehensive developer documentation, a high-quality app framework for implementing AEOMs that isn’t full of bugs, holes, and slooooow, and a few million enthusiastic app scripters across a half-dozen popular languages to make that app-side development all worthwhile. (Anyway, AppleScript’s authors are dead now, and AppleScript probably not far behind them, so caveat emptor, E&OE, YMMV, perfect is the enemy of good, etc, etc.)
It’s not brilliant, but you might find an explanation of how AEOM behaves from the client side, written with a programmer audience (Python3) in mind, a bit easier to grasp. It could probably have done with 8-foot neon flashing “It’s RPC plus Queries, not OOP!” text to really get the point across, but I guess I ran out of 8-foot neon flashing pixels that day so you’ll just have to take that as implicit. HTH
I’ve just posted an updated Bike with an updated scripting dictionary:
Lets say it was done medium quick
It’s not perfect, but I think much improved from what I started with. Most importantly I got rid of child row concept, and I think it’s much improved for that. Here’s what things look like with updated dictionary:
I wasn’t able to apply the expand/collapse/selection suggestions. I generally agree they are good, but it’s also not strait easy path for Cocoa Scripting and I have a bunch of other things I need to work on first. If needed I think I can come back to these with better implementations and just mark the existing properties as hidden.
Lots of future todo’s for Bike. I will be adding a lower level JavaScriptCore API among many other things. Anyway, thanks again for all the feedback.
collapse v : Collapse rows.
collapse document
at list of row : The rows to collapse.
[completely boolean]
expand v : Expand rows.
expand document
at list of row : The rows to collapse.
[completely boolean]
A document reference should not be passed as the direct parameter. The document object is already specified within every row X of document Y reference the user passes. Make the direct parameter list of row and remove the at parameter.
As an aesthetic improvement to these commands I would also rename the completely parameter. It’s a PITA to think of good names for Boolean parameters as AS automatically reformats a command such as:
expand aRow with completely
expand aRow without completely
Have a think about it. If you can replace that adverb with a suitable noun, code will read better. (The tidy choice would be “with[out] recursion”, but that’s far too programmer-y jargon.) Perhaps:
Verbose, but reads better in AppleScript’s weird pidgin.
You do still need add a read-only Boolean collapsed† property to the row class. This allows users to get a row’s current state.
You don’t need to worry about this property’s performance as the really important task—changing the expanded/collapsed state across multiple rows—is done by your fast commands. But it is important that users can observe a document’s current state and not be forced to blindly assume it.
–
† While you could call the property expanded and flip the boolean around, I think of false as signifying the resting state and true indicating an active state. As an outline user I would naturally assume all rows to be visible by default and must actively hide those rows I don’t want to see. Again, it’s a case of thinking “what is the user’s natural expectation” and shaping the UI to satisfy their prediction of what it is called and how it behaves.
Bike – MacInTouch https://www.macintouch.com/post/24139/bike/
Bike is a new outliner app for the Mac from Jesse Grosjean (Hog Bay Software) with a simple, friendly design built on a foundation of open file formats with support for large documents.